We Rebuilt Wandero in 3 Weeks With AI Agents
Five engineers rebuilt a production travel-operations platform from scratch in three weeks with AI agents — about $35k in tokens and 300k lines of code. Here is what got cheaper, what stayed human, and why clarity became the real bottleneck.
3 weeks. 5 engineers. $35k in tokens. 300k lines in production.
Wandero is an AI-native operating system for travel and hospitality businesses: one workspace to manage and run company operations across client conversations, files, itineraries, proposals, suppliers, follow-ups, approvals, and long-running work.
At the end of 2024, we started building the first version.
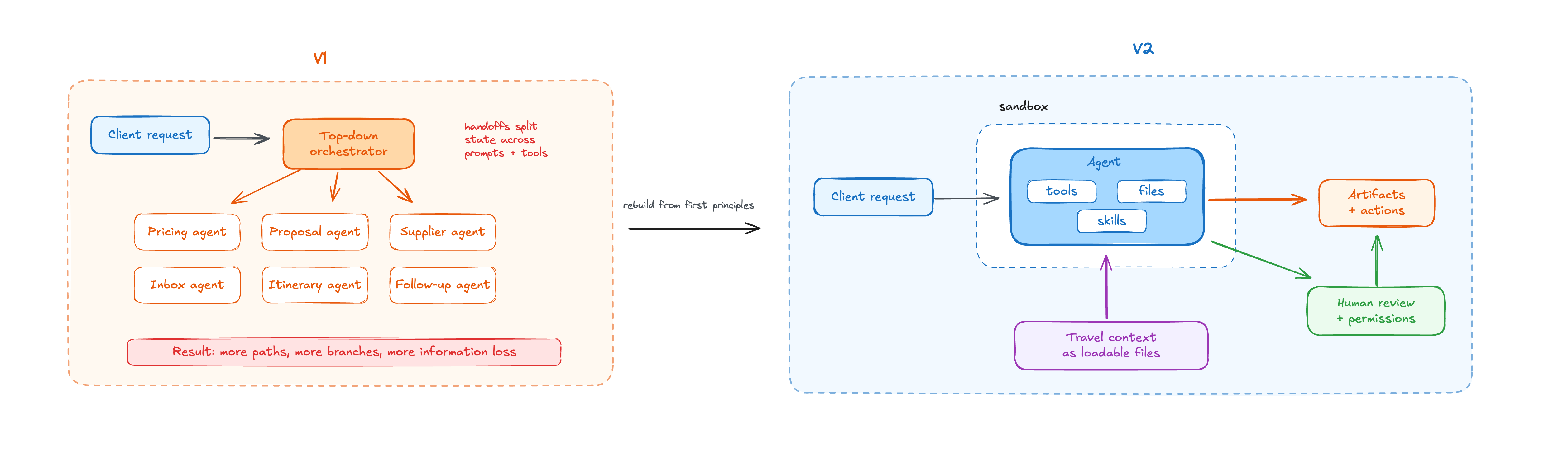
That timing matters. The agent stack was different then. Models were weaker at instruction following and tool use. Coding agents could not reliably build a large product end to end. Context engineering was not yet the thing everyone talks about now. So V1 was built the way you had to build serious agent software at the time: top down, with a lot of orchestration, a lot of product-specific logic, and humans anticipating almost every path the agent might need.
It worked. Clients used it in production for a year.
Then we rebuilt it from scratch.
Five engineers. Three weeks. Around $35k in AI token spend. About 300k lines of production code. Live by the end of week three.
This is not a story about sleeping while agents write code. The opposite happened. We worked harder than before, but the work changed. We were no longer spending most of our time typing implementation. We were running many agents in parallel, reviewing plans, rewriting architecture, checking outputs, forcing consistency, and deciding what the system should become.
That is the real shift.
Code got cheaper. Taste, judgment, context, and verification got more important.
Why the first version had to end
V1 was not a failure. In the narrow sense, we won.
We knew the travel operations problem well, and we built a system around the problems in front of us. Agencies had different supplier rules, proposal formats, approval flows, inbox patterns, ways of pricing and booking. We encoded those workflows directly.
The first version even had a complex multi-agent architecture: around fifteen agents, each with its own prompt and tools, wired together with supervisor and swarm patterns. That sounded right in theory. In practice, it created information loss. One agent would know something the next agent did not. The handoff became a product problem. Debugging became distributed across prompts, tools, and state.
Over time, we removed parts of that orchestration. But the deeper shape stayed the same: V1 was a system of hand-built paths.
Every new client request added another path. Every special supplier rule added another branch. The system prompt grew to around 26k tokens because it was trying to describe too much behavior up front. The agent had tools, but not a real environment of its own: no persistent filesystem it could treat as working memory, no isolated computer, no general surface for creating whatever artifact the task needed.
That architecture was useful because it was specific. It became painful for the same reason.
The more production taught us, the more obvious the limit became. V1 had captured real client pain, real edge cases, and real operational complexity. But the codebase was not compounding. It was accumulating.
The decision
We looked at the product we had, the problems we knew were coming, and the agent capabilities available now. The conclusion was direct: a refactor would keep us inside the old shape. The old architecture was built for weaker models, smaller context, worse tool use, and a world where we had to pre-build most of the agent's behavior.
So we made the uncomfortable call: rebuild from zero, with first principles in mind.
That did not mean throwing away the year of work. V1 was the spec.
A year of production traffic had taught us what broke: bookings with non-standard supplier rules, agency-specific proposal formats, inbox patterns, pricing edge cases, long conversations that changed direction, files that had to be carried forward across sessions. The old system showed us what the new system should not look like.
That is why legacy code can be valuable even when you delete it. Thariq made the same point after the Bun rewrite: legacy codebases can become a source for distilling code into new forms. That was true for us. V1 was not the destination. It was the training data for our taste.
The expensive part was no longer writing the code. The expensive part was deciding what code should exist.
If you assume coding agents give you more free time, our experience says otherwise. They increase the number of loops you can run. That means more plans to review, more architectural choices to make, more consistency to enforce, more failures to interpret, and more responsibility for the final shape of the product.
The human role moved up the stack, but it did not disappear.
How we worked
Before serious implementation started, we wrote the system down.
Architecture plan. Module boundaries. Code practices. Error handling rules. Logging conventions. What V1 got wrong. What we wanted to keep. What we wanted to remove.
The product principles were written down before implementation:
- flexible artifacts
- simple primitives
- no pre-baked client flows
- no static fields pretending to be generality
- no orchestration that hides information from the next step
The agents wrote a lot of those documents with us. We reviewed them, argued with them, asked what would break, asked what we would regret in six months, asked why this design was better than the alternatives. Only then did we let implementation begin.
This part matters because "give an agent the repo and ask it to build" is not a process. It is a coin flip. The discipline is closer to what Peter Steinberger calls agentic engineering: keep the human in the loop, make the agent validate its own work, and review evidence instead of trusting generated code.
Our loop looked more like this:
- Write or update the plan.
- Let the agent implement the next bounded piece.
- Make the agent run the code, tests, migrations, and checks itself.
- Give it access to logs, traces, screenshots, and runtime errors.
- Make it explain the failure before fixing it.
- Review the result, then repeat.
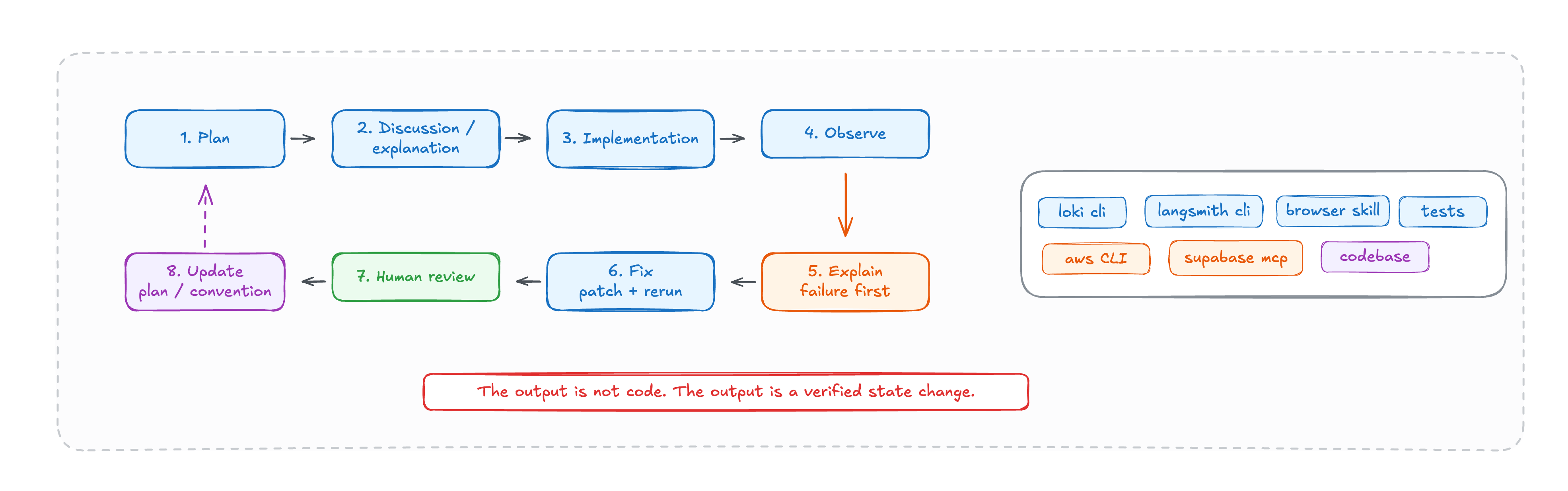
The agent had access to the same categories of tools we use as engineers: cloud CLIs, database migration tools, test runners, trace inspection, log search, browser screenshots, shell access, and repo search. It did not only read code. It could run the system, see what failed, inspect the evidence, and patch the problem.
That was the important distinction. The agent was not getting only source files and prompts. It was getting the environment around the source files.
Most agent failures we hit were not solved by better wording. They were solved by improving the environment: adding a missing check, making state visible, giving the agent a clearer file convention, making a test runnable, exposing a trace, tightening a permission boundary, or turning an implicit rule into a document the agent could load later.
The first week almost killed the rewrite. Sandbox isolation, filesystem persistence, and sync between the sandbox and the control plane were all unstable at once. The model side had a different problem: it was capable enough to make the wrong move confidently, including producing inconsistent artifact formats across similar tasks.
The fix was not one magic prompt. It was harness work plus stricter conventions: stable templates, clear seams, repeatable checks, and files that made the expected behavior visible.
That is the lesson I would keep: do not only fix the agent. Fix the world the agent is operating inside.
The agent worked in artifacts, not chat
The most useful change in how we collaborated was almost invisible: we stopped treating the chat window as the place where thinking happened.
When an agent researched a problem, planned a module, or proposed an architecture, it did not just reply in the conversation. It produced an artifact — a Markdown document with the plan, the tradeoffs, and an ASCII diagram of the design, or a small HTML page we could open and read. We reviewed that file, left our feedback inside it, and the agent kept working against the same document.
This sounds minor. It was not. A chat log is a bad place to make a decision: you scroll, you lose the thread, you re-read the same reasoning three times. A document is a good place to make a decision. It has structure, it holds still, and both sides can point at the same paragraph.
Thariq put it directly: "The chance of someone actually reading your spec, report or PR writeup is much much higher if it's in HTML." Elvis Saravia made the sharper point: the artifact is "an important verification layer." When an agent works for an hour, you do not want to audit it by scrolling a transcript. You want it to hand you a document.
In practice our agents produce todo.md files to track multi-step work, markdown design proposals with ASCII architecture diagrams written for a specific reviewer, plan files they research into and then build against, and HTML artifacts a client can open directly. The artifact became the unit of work and the unit of review at the same time.
The chat is where the agent talks. The artifact is where the work happens.
One caveat we learned: this works because these are documents you read once and act on. Raw HTML is the right format for a throwaway plan or a one-time report; it is the wrong format for a surface you ship and maintain. Use the artifact for thinking, not as your product.
What became cheap
The agent was strongest where the work had clear shape:
Boilerplate. CRUD endpoints, schemas, migrations, request and response types, controllers, service wiring. Hours of typing collapsed into reviewable implementation.
Tests. The agent could generate unit and integration tests quickly, run them, read the failures, and patch its own mistakes.
Infrastructure. If the task had a CLI, a failure message, and a way to verify success, the agent could usually make progress. That included migrations, deployment wiring, and environment configuration.
Logs and debugging. This one surprised me. An agent turned out to be a better log reader than a person. It reads every line, does not anchor on the first plausible cause, and does not get bored and route around the flaky failure everyone has been avoiding for months. Point it at the logs and traces and it deep-dives, filters the noise, and finds the real problem — fast, and for almost nothing. As Eric Zakariasson put it when Cursor shipped its debug mode, "agents were never bad at debugging — we were making them debug blind." The model did not get smarter here. We just stopped hiding the evidence from it.
Consistency. This was the biggest win.
"Make this module follow the same pattern as that module" became a practical instruction. In a 300k-line rewrite, that matters more than people expect. A large codebase does not fail only because features are missing. It fails because every feature expresses a slightly different architecture.
Agents made repeated implementation cheap enough that we could rewrite parts several times instead of negotiating with the first version. That changed how we measured work. The question became less "how long will this take to type?" and more "do we know what good looks like?"
This is the same economic shift behind experiments like Lee Robinson building Pixo with 520 agents and $287 in tokens, moving cursor.com out of a CMS in three days, and Cursor's FastRender browser experiment. Once the work is specified and verifiable, implementation and distillation become cheap enough to rerun.
Anthropic describes the same shift from inside the frontier lab: more than 80% of their production code is now written by Claude, and the doing — writing the code, running the experiment, producing the result — "now costs almost nothing in human time." What stays scarce, in their telling, is research taste and judgment. That matched what we felt: the typing got cheap, the deciding did not.
What stayed human
The human work did not go away. It became more concentrated.
Architecture. We still had to decide the shape of the system. An agent can implement almost any architecture you describe, including the wrong one. It cannot know which tenancy model fits your business, which tradeoff is acceptable for clients, which abstraction will survive the next six months, or which feature should not exist.
Taste. We still had to define what good meant.
For a travel agency or a hotel, "works" is not enough. The proposal has to look right. The itinerary has to feel client-ready. The pricing has to match how that business actually sells. The agent can generate options, but somebody has to know which option is good.
Integration. We still had to make the system work end to end. Individual modules were often clean. The hard part was making a real customer workflow pass through inbox context, company rules, files, generated artifacts, approvals, and follow-up actions without losing meaning.
Management. We still had to manage the agents.
Running more agents does not reduce management. It increases it. You get more parallel progress, but also more branches of thought to reconcile. You need to know when to accept, when to reject, when to ask for alternatives, and when to stop patching and rewrite the whole piece.
That is why this did not feel like outsourcing engineering. It felt like managing an engineering system with more parallel loops than one person could write by hand.
One honest note on timing: we ran this only a few weeks ago, and the tooling has already moved. The popular agent harnesses are racing to add features for long-running agents — dynamic workflows in Claude Code (triggered with the keyword "ultracode"), where the agent writes its own task-specific harness; goal modes that hold the agent to a hard completion criterion; loops that keep it running until the work is actually done. Part of the management I just described — reconciling branches, deciding when to stop patching — is starting to move into the loop itself. A rebuild like this is already easier than it was when we ran it, and the human job keeps moving up: less hand-reconciliation, more setting the goal and the gate.
The design patterns that survived
We expected to build a travel-specific architecture. We ended up with a general agent harness where travel and hospitality context is loaded into a small set of primitives.
That is not unique to us. It is the same broad direction visible in modern coding agents: Claude Code, Codex, Cursor, Manus, OpenClaw. The useful system is not just the model. It is the model plus runtime, tools, memory, permissions, and verification. LangChain calls this the agent harness. We ended up building one for travel and hospitality operations.
1. An isolated computer per conversation
Each conversation gets its own sandbox and filesystem. The agent can work with files, run tools, and keep session state without seeing what it should not see.
Security is a runtime property, not a sentence in the prompt.
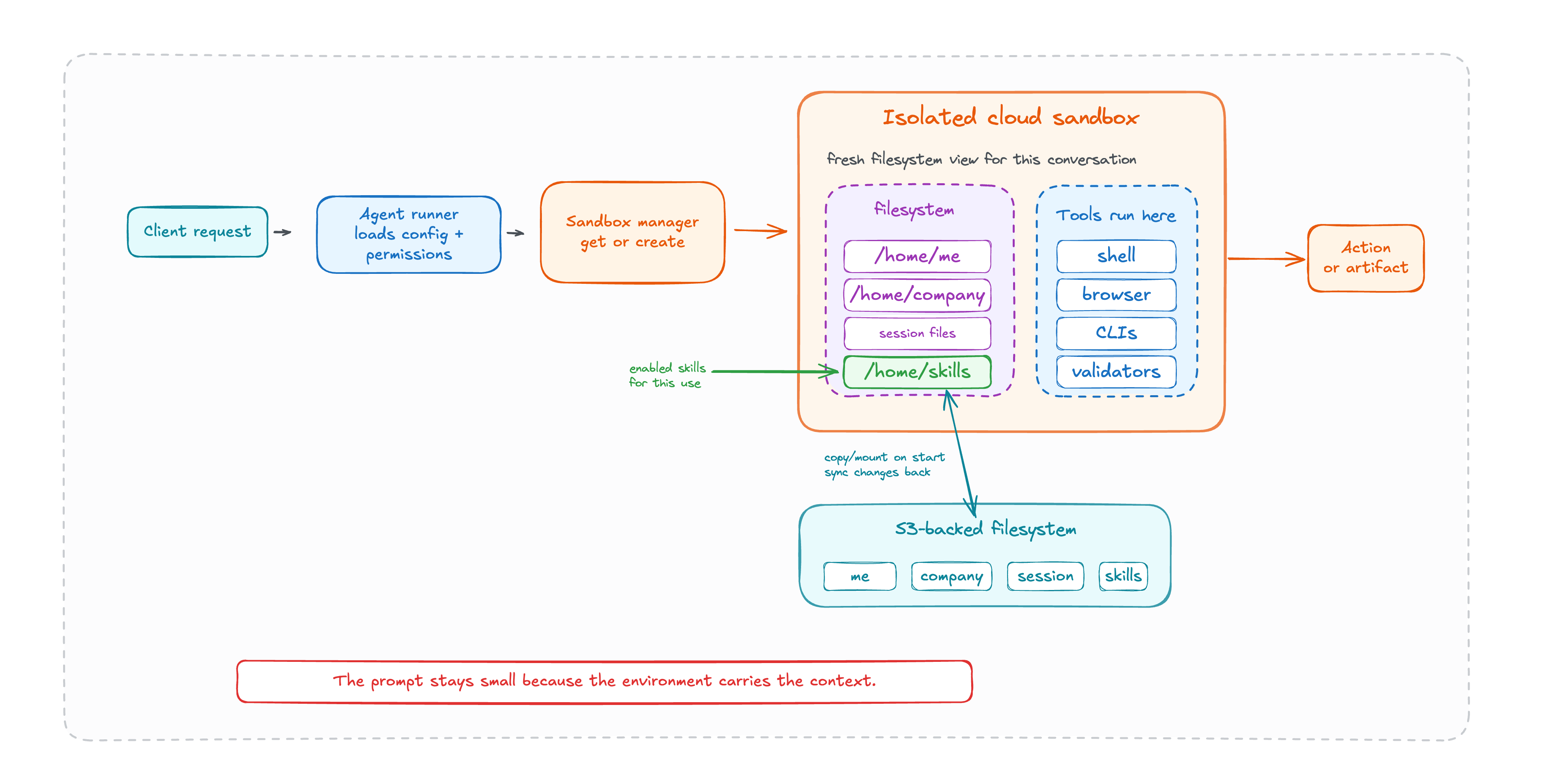
2. Files as the interface
Company guidelines are files. Supplier rules are files. User preferences are files. Session work is files. Skills are files. The agent can ls, search, read, write, and carry work forward in a way that feels closer to a developer using a repo than a chatbot reading a hidden database.
User settings? A file the agent reads and edits. Domain documentation? Files. Past sessions? Files. The agent's own capabilities? Files in a skills directory it can search.
A simplified version of what the Wandero agent sees looks like this:
/
├── company/ # org-wide context
│ ├── overview.md
│ ├── guidelines.md
│ ├── memory.md
│ │
│ ├── settings/ # structured config
│ │ ├── profile.json
│ │ └── pricing.json
│ │
│ ├── assets/
│ │ └── logo.png
│ │
│ ├── policies/
│ │ ├── payment.md
│ │ └── terms-and-conditions.md
│ │
│ ├── resources/
│ │ └── seasonal.md
│ │
│ └── inventory/
│ └── accommodation/
│ └── marriott-downtown/
│ └── content.md
│
├── booking/
│ ├── instruction.md
│ └── dashboard.jsx
│
├── me/ # user-level context
│ ├── memory.md
│ └── instructions.md
│
├── sessions/
│ ├── current/ # read-write
│ │ ├── itineraries/
│ │ ├── attachments/
│ │ └── working-files/
│ │
│ └── other_sessions/ # read-only
│
└── skills/ # attached skills
└── {skill-slug}/
├── SKILL.md
└── scripts/
This is why the "files are all you need" idea from Jerry Liu matters. Files are not just storage. They are memory, permissions, configuration, skills, and working state in a form both humans and agents can inspect.
3. Skills instead of a giant prompt
Instead of stuffing every capability into the system prompt, capabilities live as folders with instructions, scripts, and scoped bindings. The agent discovers what it can do by reading the skills available to that session.
This is how we moved away from V1's 26k-token prompt. V2 does not need to tell the agent everything up front. It needs to give the agent the right environment and let it load the right capability when needed.
4. Progressive disclosure
Several hundred markdown files would be useless if the agent loaded all of them at once. It does not. It reads a small index, then opens the specific plan, convention, skill, or memory file needed for the task.
That is the same reason a human engineer does not memorize a whole repo. You search, open the file that matters, and follow the local context.
Drew Breunig makes the same point about what to write down: humans do not need exhaustive documentation, they need a mental model — the agent can find the details. So you write only enough to build that model and trust the agent to pull the rest.
5. Generated artifacts
V1 had static forms and fixed fields. V2 has a chat surface plus a viewer. If the agency needs a dashboard, proposal, spreadsheet, itinerary, supplier comparison, or internal report, the agent generates the artifact for that task.
The pattern is simple: fewer fixed product surfaces, more general capabilities, more context at runtime. This is the bitter lesson applied to product architecture: when the model is capable enough, general mechanisms beat hand-coded special cases. Daniel Miessler calls the same trap bitter lesson engineering: over-scaffolding the model can become the thing that stops it from working.
What the experiment proved
We started the rewrite as an experiment. We did not know whether a small team could rebuild a production system this way and reach the quality bar we needed.
Now I think the answer is yes, with a serious caveat.
Agents are capable enough today to build large production systems quickly. This rewrite was not a toy app, not a demo, and not a weekend prototype. It was a real platform used by real clients, in a domain where mistakes cost money and trust.
But agents are not a substitute for knowing what you want.
This was easier for us because V1 had already taught us the problem. We knew the pain. We knew what the code should not look like. We had production examples, failure modes, edge cases, and customer workflows. We were not asking the model to discover the business from nothing. We were asking it to build a better system from a year of hard-earned evidence.
That distinction is important.
The coding agent changes the economics of building. It makes implementation cheaper, rewrites more realistic, and iteration faster. And the agents we use now are already stronger than the ones this rewrite depended on, so the curve is still moving.
But it does not remove the need for first-principles thinking. If anything, it punishes vague thinking faster because vague direction now produces a lot of code very quickly.
The biggest change for me is not only code. It is how daily work feels.
Agents help brainstorm architecture, research alternatives, simulate customer workflows, inspect logs, write tests, generate artifacts, and challenge assumptions. They turn one engineer into a manager of many loops. That is exciting, but it is not passive.
The future I see is not "AI builds while humans relax."
It is more intense than that.
Humans decide what is worth building, what good looks like, what tradeoffs matter, and when the output is not good enough. Agents make the search space bigger and the loop faster.
That is the shift we felt during the rewrite.
The bottleneck is no longer typing.
The bottleneck is clarity.